Joseph Keshet

Joseph Keshet

Some of the research projects are explained here. The are ordered in a reverse chronological order.
Spoken Hebrew Corpus and Models: Speech-to-Text and Text-to-Speech
Spoken Hebrew Corpus and Models: Speech-to-Text and Text-to-Speech Application The limited availability of digital products in Hebrew largely stems from the absence of substantial Hebrew data corpora for machine learning training. Notably, services such as speech-to-text and text-to-speech are rarely incorporated into commercial products and are entirely absent for research purposes. Furthermore, upcoming NLP… Continue Reading Spoken Hebrew Corpus and Models: Speech-to-Text and Text-to-Speech
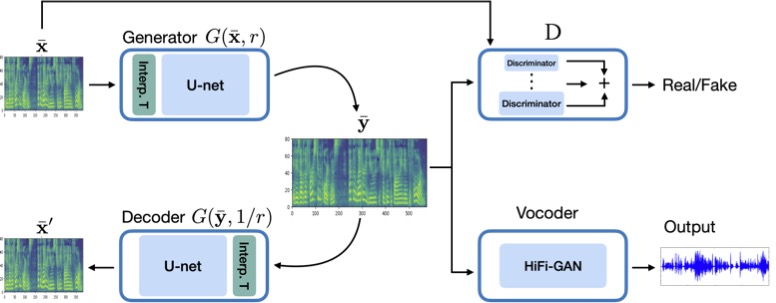
Speeding up and slowing-down speech with exceptional quality Written by Eyal Cohen. Originally published on Medium on JAN 5, 2023. This post is about our paper ScalerGAN which was accepted for publication in IEEE Signal Processing letters. It was written with the help of Yossi Keshet and Felix Kreuk. Whether it is podcasts, WhatsApp voice… Continue Reading Speeding up and slowing-down speech with exceptional quality
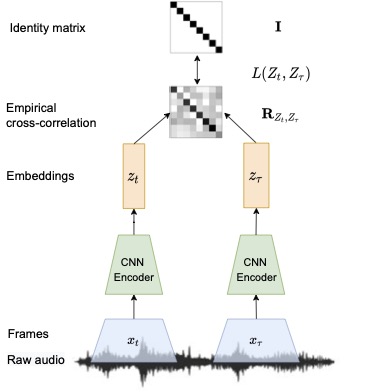
Self-supervised Speaker Diarization We propose an entirely unsupervised deep-learning model for speaker diarization. Specifically, the study focuses on generating high-quality neural speaker representations without any annotated data, as well as on estimating secondary hyperparameters of the model without annotations. The speaker embeddings are represented by an encoder trained in a self-supervised fashion using pairs… Continue Reading Self-supervised Speaker Diarization
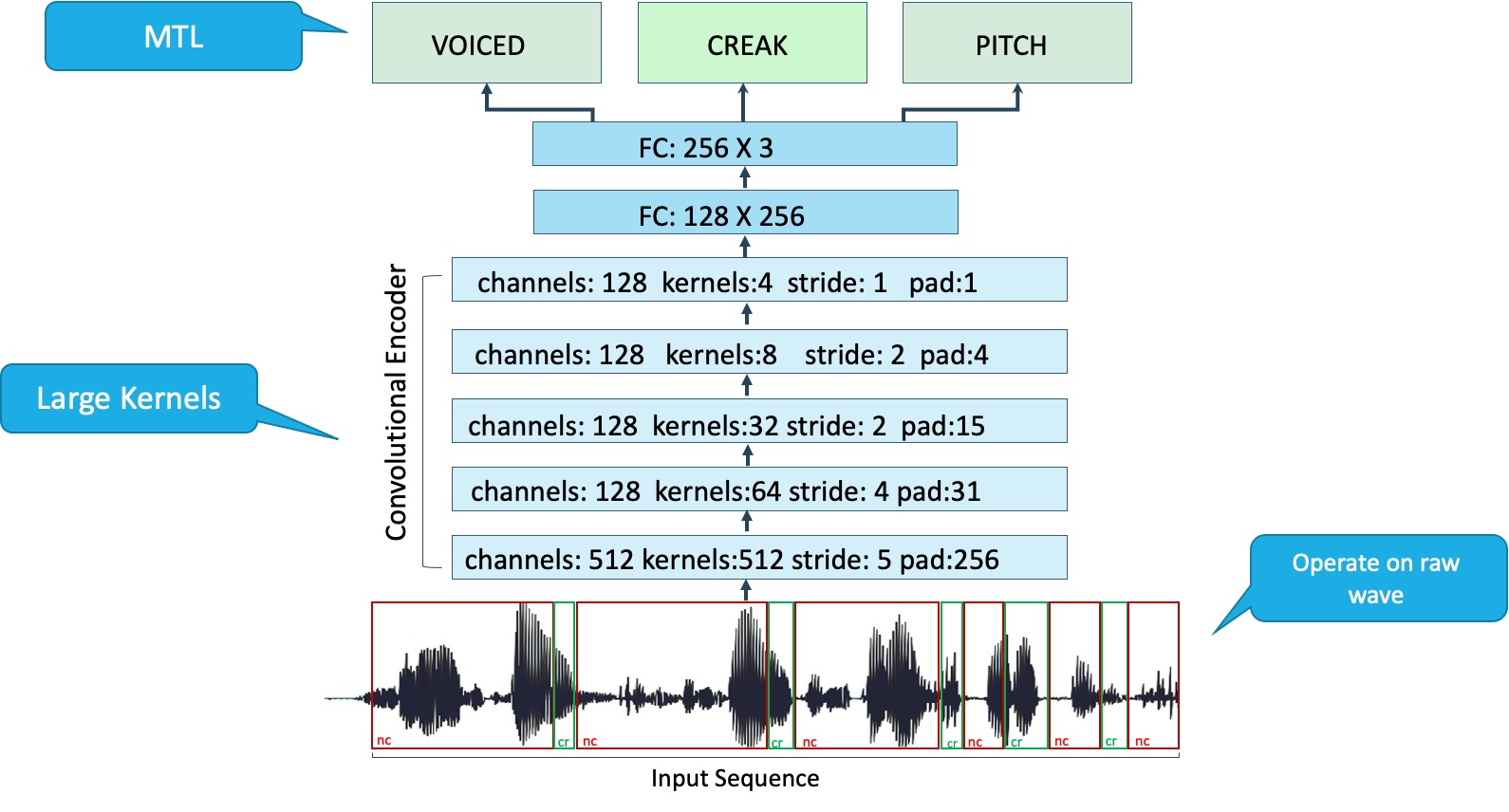
DeepFry: deep neural network algorithms for identifying Vocal Fry Written by Roni Chernyak with the help of Eleanor Chodroff, Jennifer S. Cole, Talia Ben Simon, Yael Segal, Jeremy Steffman. Originally published on Medium on Sept 2, 2022. This post is about our paper DeepFry which was accepted for publication at Interspeech 2022. What do Britney… Continue Reading DeepFry: deep neural network algorithms for identifying Vocal Fry

AI for Speech Therapy and Language Acquisition This is a blog post on our paper regarding correcting mispronunciations in speech that was accepted for publication at Interspeech 2022. This was the work of Talia Ben Simon and Felix Kreuk together with Yaki Cohen and Faten Awwad from Rambam Medical Center. Learning a new language … Continue Reading AI for Speech Therapy and Language Acquisition
The Ubiquity of Machine Learning and its Challenges to Intellectual Property Written by Carsten Baum. Originally published on Medium on Aug 9, 2018. In this short blog post, I will discuss some recent work of myself and Yossi Adi, Joseph Keshet and Benny Pinkas from Bar Ilan University as well as Moustapha Cisse from… Continue Reading The Ubiquity of Machine Learning and its Challenges to Intellectual Property