Speeding up and slowing-down speech with exceptional quality
Joseph Keshet

Joseph Keshet

Speeding up and slowing-down speech with exceptional quality
Written by Eyal Cohen. Originally published on Medium on JAN 5, 2023. This post is about our paper ScalerGAN which was accepted for publication in IEEE Signal Processing letters. It was written with the help of Yossi Keshet and Felix Kreuk.
Whether it is podcasts, WhatsApp voice messages, Youtube, or even TikTok videos, listening to audio content has become an integral part of our daily life. When listening to audio, it is often desired to change speech speed while maintaining the speaker’s timbre and pitch. In this post, we will skim over the speech synthesis procedure, the GAN architecture and introduce a novel deep learning-based algorithm for changing the speed of speech called ScalerGAN.
Traditional Algorithms
Existing approaches are based on advanced signal processing, which are often based on time-domain [1] or spectral-domain [2–3] Overlap-Add (OLA). All those methods assume quasi-stationarity of the input speech. Hence they suffer from perceivable artifacts in the generated waveforms. Furthermore, while the generated speech of such algorithms is a linear transformation of the input, the change in our speaking speed is often not constant or linear. Subjectively, it seems that the quality of modified speech can be improved, especially for extreme slow-down or speed-up, and it remains a challenge to maintain a high speech quality at all speeds.
Speech Synthesis
Most modern speech synthesis techniques [4–5] are formulated with two main steps. The first step is to generate time-aligned spectral features from the raw waveform input, such as Mel-spectrogram. The second step applies a vocoder, generating a time-domain waveform conditioned on the predicted spectral features. Our algorithm focuses on the former, i.e., generating spectral features corresponding to a time-scaled modified speech by the desired rate. The last step of converting the spectral features to a waveform is implemented with HiFi-GAN.
Generative Adversarial Networks(GAN)
Generative Adversarial Networks (GANs). GAN is a class of machine-learning framework that includes a generation network that generates candidates and a discriminative network that evaluates them. The networks are trained simultaneously using a combined loss function [6]. We borrow ideas from CycleGAN [7], StarGAN [8], and InGAN [9]. These algorithms convert images from one domain to another domain. To improve the target image quality and to preserve consistency, the generated image is converted back to the original domain using an additional generator or the same generator. These algorithms use one or two discriminators to stir the generator further to generate images that cannot be distinguished from “real” images.
A New Approach — ScaleGAN
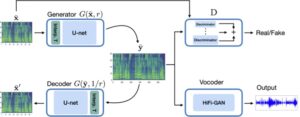
Inspired by the success of speech generation using GANs, we propose a novel unsupervised learning algorithm for changing the speed of speech named ScalerGAN. In ScalerGAN, The speech is time-adjusted to the desired rate using a generator. Then, the quality of the generated speech is improved in two ways:
- Using a discriminator that classifies whether the speech is real or synthetic (fake);
- Using a decoder that converts the time-adjusted speech back to the original rate to preserve consistency. The decoder is implemented by using the generator but with an inverse rate.
Recall that the main challenge of designing a time-scale system based on machine learning is that we do not have training examples of different rates.

Flexible rate Generator
The Generator consists of two components; a linear transformation by a a given rate and a deep U-net network. The input to the Generator is spectrogram and the desired rate 𝐫 and the output is a new spectrogram which is time-scaled to 𝐫.
The decoupling between the U-Net and the linear transformation allows us to train the Generator on speech spectrograms regardless of specific rate 𝐫 while generalizing to any rate at inference time. The U-net learns to transform linearly interpolated spectrograms to spectrograms that represent the original speech. This is achieved by two components; a discriminator and a decoder.
Multi-Scale Discriminator
The discriminator is a function that is trained to discriminate between real input spectrograms and synthetically generated spectrograms. The speaking rate is influenced by the speed of articulation and can influence unevenly on the spectrograms. For example, changes in the rate of utterance would tend to be absorbed more by the vowels than the consonants.
To allow the discriminator to work on such variations, it is designed as a set of several sub-discriminators, each of which operates at a different scale of the spectrogram. The input to each sub-discriminator is a different down-scaled version of the input spectrogram.
Each sub-discriminator is a classifier, composed of convolutional layers, that predicts whether its input is derived from a real signal or a synthetic one (“fake”).
The output of the classifier is not a single decision but rather a probability matrix. Each element of this matrix corresponds to a patch in the input, and represents the probability of how realistic the patch is.
The probability matrices are up-scaled to the same size and aggregated by a weighted sum over all outputs.
Decoder
The decoder’s goal is to reconstruct the original signal from the synthetic one. It is implemented using the generator where the output spectrogram and the multiplicative inverse of 𝐫 (1/𝐫) are used as input parameters. This encourages The generator to avoid mode-collapse and maintain the same spectral content before and after the model generation.
Final notes
In this post, we introduced the problem of speeding up or slowing down speech, explained why the traditional approaches for this task isn’t good enough, presented The GAN architecture and proposed a new and deep-learning method for this task. However, there is still work to be done. For instance, in our research we only focused on speech and we didn’t investigate the field of music.
Audio examples can be found here:
For more details on our implementation, our repo for ScalerGAN is publicly available here.
References
[1] W. Verhelst and M. Roelands, “An overlap-add technique based on waveform similarity (WSOLA) for high quality time-scale modification of speech,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 1993, vol. 2, pp. 554–557.
[2] J. Laroche and M. Dolson, “New phase-vocoder techniques for pitchshifting, harmonizing and other exotic effects,” in Proc. IEEE Workshop Appl. Signal Process. Audio Acoust., 1999, pp. 91–94.
[3] T. Karrer, E. Lee, and J. O. Borchers, “PhaVoRIT: A phase vocoder for real-time interactive time-stretching,” in Proc. Int. Comput. Music Conf., 2006, pp. 708–715.
[4] J. Shen et al., “Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 4779–4783.
[5] W. Ping et al., “Deep voice 3: Scaling text-to-speech with convolutional sequence learning,” in Proc. Int. Conf. Learn. Representation, 2018.
[6] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst., vol. 27, 2014, pp. 2672–2680
[7] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis., 2017, pp. 2223–2232.
[8] Y. Choi, M.-J. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo, “StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 8789–8797.
[9] A. Shocher, S. Bagon, P. Isola, and M. Irani, “InGAN: Capturing and retargeting the ‘DNA’ of a natural image,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., 2019, pp. 4492–4501.