The Ubiquity of Machine Learning and its Challenges to Intellectual Property

Joseph Keshet

Joseph Keshet

The Ubiquity of Machine Learning and its Challenges to Intellectual Property
Written by Carsten Baum. Originally published on Medium on Aug 9, 2018.
In this short blog post, I will discuss some recent work of myself and Yossi Adi, Joseph Keshet and Benny Pinkas from Bar Ilan University as well as Moustapha Cisse from Google Research (who worked at Facebook AI Research during the project). Our article will appear at USENIX Security 2018. The text is targeted at a non-technical audience and I will keep it free from any formulas for as much as possible. If you want to directly dive into the technical parts, just have a look at the arxiv article. If you have any feedback then feel free to contact me by e-mail. As there have been multiple works on this subject I will focus on our paper, which contains references to concurrent work by other groups.
Machine Learning in a nutshell
Computers are embedded in every device around us and modern life cannot be thought without these wonders of technology. But even though such marvels of human ingenuity allow me to do incredible things (like typing this blog post in a coffee shop in Tel Aviv in order for you to read thousands of kilometers away on this planet), they are actually surprisingly dumb. Most of the time, they just apply a fixed algorithm to some input data in order to generate output data.
Machine Learning (ML) is a branch of computer science that trains computer algorithms to recognize structures or patterns within input data. As an example, think you have a stack of thousands of old newspapers and want to 1) find out which of these are issues of the New York Times; and 2) extract the advertisements from all of them. Doing these tasks manually is tedious. But if these newspapers are available in digital form, then one can use ML to help. To accomplish this, one trains digital algorithms to generate models (configurations of the ML classification algorithm), in order to fulfill certain tasks:
- In the first case, what we want to do is called classification of inputs. For this task, we would generate a model which, by looking at an image, tells if this image indeed is a scan of a New York Times or if it depicts something completely different.
- In the second case, the model would perform a task which is called segmentation. Here, we train the model to parse through input images, look at the different columns that a newspaper has, and output those areas of a newspaper that potentially are ads.
In our work as well as the rest of this post, the focus is on classification.
If you let a human perform the task at hand, then with a high chance she may not get everything but most of it right (assuming a continuous supply of caffeine), so we can use this as a benchmark. If a model performs close to what it should do (e.g. to what a human would do), then we call it "accurate." Thus, a model which generally is right on more inputs is said to have higher "accuracy" than one which errs with a higher chance. Recently, a certain class of ML algorithms called Deep Neural Networks (DNNs) have been shown to outperform even highly specialized techniques at most ML tasks. Whenever you heard about the AI revolution or some other magic which computers can now do as good as humans, then chances are high that DNNs play a vital part in this. I’ll not talk about DNNs in any more detail, but want to stress that our work is mostly focused on this class of ML algorithms.
Why you want to guard your models?
The "magic" of DNNs comes with a drawback — training these requires large amounts of data and computational power. Big companies use specialized chips for their ML training. A small firm is not able to make such investments if it wants to include DNN technology into its products. For this reason, companies with training capabilities such as Google, Amazon and Microsoft sell "Machine Learning as a Service" (MLaaS) as part of their Cloud computing products.
But as models are simply zeroes and ones, they can easily be copied and given to someone else. If I want to offer a
specialized MLaaS service, this may ruin my business model as a seller: customers may just distribute the purchased model to everyone else. I therefore want to take precautions against such theft of my intellectual property. Even worse, classic mechanisms for intellectual property protection such as Digital Signatures are bound to fail. This is because one can re-train a model and introduce subtle changes whilst not changing the accuracy at all, whereas Digital Signatures fail as soon as a single bit of the signed object is altered. I can of course provide access to my model through an API which my customers will have to use. For certain applications, this might nevertheless not be possible. For example, my customer may have to keep his queries to the DNN private as they are medical data or he may want to use ML in applications which are time-constrained or where no connection to the internet is available, like in cars.
Watermarks
A solution to this problem is to embed a watermark into a model. A watermark is a structure which is imprinted into an object of value during the production process, such as to be able to identify its origin and to thereby distinguish fake from real. Such watermarks have long been used and you might be familiar with them: just take one of the bank notes from your purse and hold them against the light. You will most likely see a specific image which only becomes visible under this condition. In bank notes, such watermarks rely on the difficulty of producing them and they are there to prevents forgeries.
But digital data is easy to duplicate by just copy-pasting it. For images, such watermarks are sometimes embedded by altering the whole picture (which makes the object then potentially useless). A better way is to alter the item to have certain flaws, but to make these imperceptible and undetectable to anyone who lacks special information about them. Therefore, there exist no strategy to remove such a watermark, while any general strategy that weeds out all potential traces of such intended deviations would make the data useless. This has been used before to protect media or in cryptographic research. It is possible and likely that videos and music that are distributed online (e.g. by Amazon, Netflix and the likes) contain a digital proof showing who purchased the item, which prevents you from redistributing it arbitrarily.
Watermarks for ML algorithms
For an ML algorithm we have a criterion of its quality which was mentioned above — the accuracy. Our solution changes the model so that the change in the accuracy is minimal. In our work on watermarking ML models, on the expected inputs of the model it will perform as good as it did before, because we plant the targeted errors outside the expected input distribution.
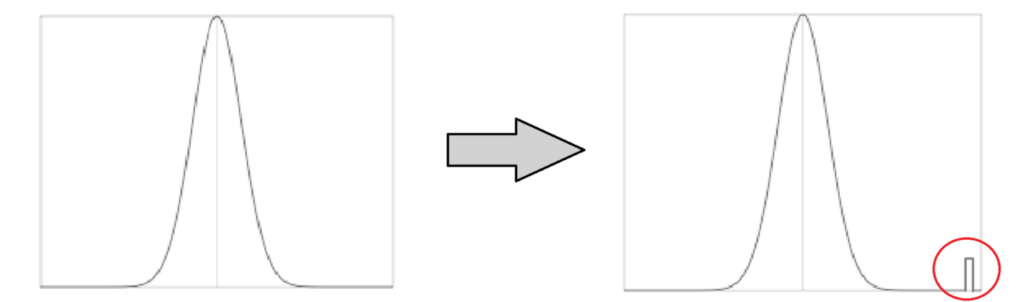
As a very simple example of this, consider an algorithm that learns the function from the image above. The inputs which we can later expect are tightly concentrated around the center, as the function is zero outside of this. But instead of the function on the left side, we now learn the modified function on the right side, which is possible as DNNs have astonishing capacities in learning functions due to the large number of parameters. For inputs which follow the expected input distribution, the user does not notice a loss in accuracy. At the same time, he can only detect the watermark if he tests on a very large number of inputs.
This ability to essentially learn a second, hidden input distribution has been exploited in other works, but mostly for nefarious purposes. In particular, we show that one of these works (called BadNets) which allows to plant backdoors in a ML model, can be leveraged for our purposes. In the paper, we outline a mathematical connection between watermarking and backdooring of models. To achieve this, we found a cryptographic definition for watermarking ML models. It is based on the observation that there are two obvious attacks against a watermark: the attacker can train a new model from scratch which performs the task, or just replace the model that he received with another model independent of it. Both of these attacks remove the watermark but are completely useless since the first attack requires computational resources that are similar to those used by the party which generated the model, and the second attack destroys the accuracy of the model. A good watermarking scheme is one which is only susceptible to these useless attacks.
In other words, we say that a watermarking scheme is secure if there are no possible attacks where the attacker invests much less computation than what is needed to generate the model from scratch, and yet generates a model which is almost as accurate as the original model. There also has been concurrent work on the subject, but I therefore refer the reader to our article. Interestingly, one proposal of IBM researchers follows a related approach and appeared recently at AsiaCCS 2018.
Experiments
To give evidence that our approach is sound, we ran experiments on multiple datasets to verify the following claims:
- This watermark strategy does not interfere with the task.
- Our watermarks are hard to remove.
In our experiments, we chose CIFAR-10, CIFAR-100 and ImageNet as datasets as these are standard benchmarks in the ML community. The images on which we train the model to deliberately misclassify (which we in the paper and the table below refer to as Trigger Set) were chosen as random images which were unrelated to the data from the dataset. For each such Trigger Set image, a class was randomly assigned during the watermarking process. I will now present some of our results.
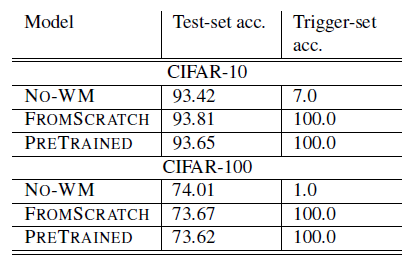
It can be seen in the table above that the Trigger Set images were always classified as trained, i.e. that the watermark is correctly placed. At the same time, the change in the accuracy with or without the watermark is negligible.
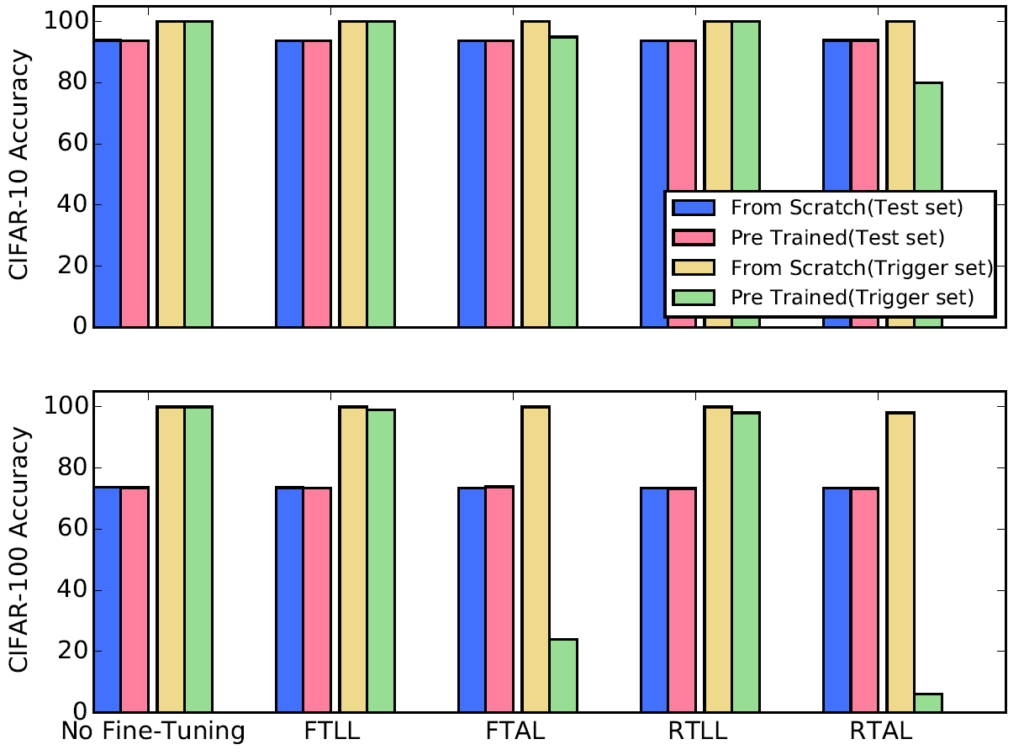
Furthermore, we ran experiments that attempt to identify and remove the watermark. The largest class of attacks can be subsumed as Fine-Tuning, where one attempts to alter a model such as to train it to a different but related task. Here, we saw an interesting behavior: if the watermark is embedded during the training, then it is stable under fine-tuning. On the other hand, if it was planted after the training phase, then fine-tuning actually removes it. This can be seen as a bonus feature for MLaaS: if a customer adds an additional watermark to claim ownership, then such an attempt can be detected.
TL;DR:
Our work allows to embed a watermark into Deep Neural Network models to protect them against theft. We give a theoretical argument for the security of our approach and show the robustness against removal experimentally.