DeepFry: deep neural network algorithms for identifying Vocal Fry

Joseph Keshet

Joseph Keshet

DeepFry: deep neural network algorithms for identifying Vocal Fry
Written by Roni Chernyak with the help of Eleanor Chodroff, Jennifer S. Cole, Talia Ben Simon, Yael Segal, Jeremy Steffman. Originally published on Medium on Sept 2, 2022. This post is about our paper DeepFry which was accepted for publication at Interspeech 2022.
What do Britney Spears, Zooey Deschanel, Scarlett Johansson, and Kim Kardashian all have in common? They all use the tonal quality of vocal fry, a type of creaky sound that occurs when the voice drops to its lowest register. And men use it too. It was mentioned a lot recently: from how celebrities use it, specifically how Kim Kardashian and rappers use it to sound sexier, and how it has become a language fad by young women. A worried grandma even wrote a letter to the Chicago Tribune complaining that her 8-year-old granddaughter “is now emulating her teacher’s voice and, not only has her beautiful singing voice suffered, it’s distressing to me that her strong, clear speaking voice may be forever lost.” Apparently, that won’t happen.
In this post, we will introduce what vocal fry is, the issues it poses to various signal processing and machine learning-based algorithms, and introduce an improved deep learning algorithm to identify it.
Characteristics: A Low and Irregular Pitch
Air coming from the lungs pushes against the vocal folds forcing an opening starting at the bottom of the vocal folds and moving upward. As the vocal folds separate at the upper edge, the lower portion closes, just as an elastic band snaps back after being stretched. With continued upward air pressure, the vocal folds are again forced open at the bottom, and again close shut, in a repeating pattern. The frequency of this vibrating pattern (the number of open-shut cycles per second, also termed fundamental frequency or f0) determines the perceived pitch of the voiced sound. During vocal fry, the vibrations are irregular, because the vocal cords are somewhat relaxed during the closure, and the airflow from the lungs decreases.
This results in slower and irregular vibrations, which we hear as a creaky voice quality that is also lower in pitch.
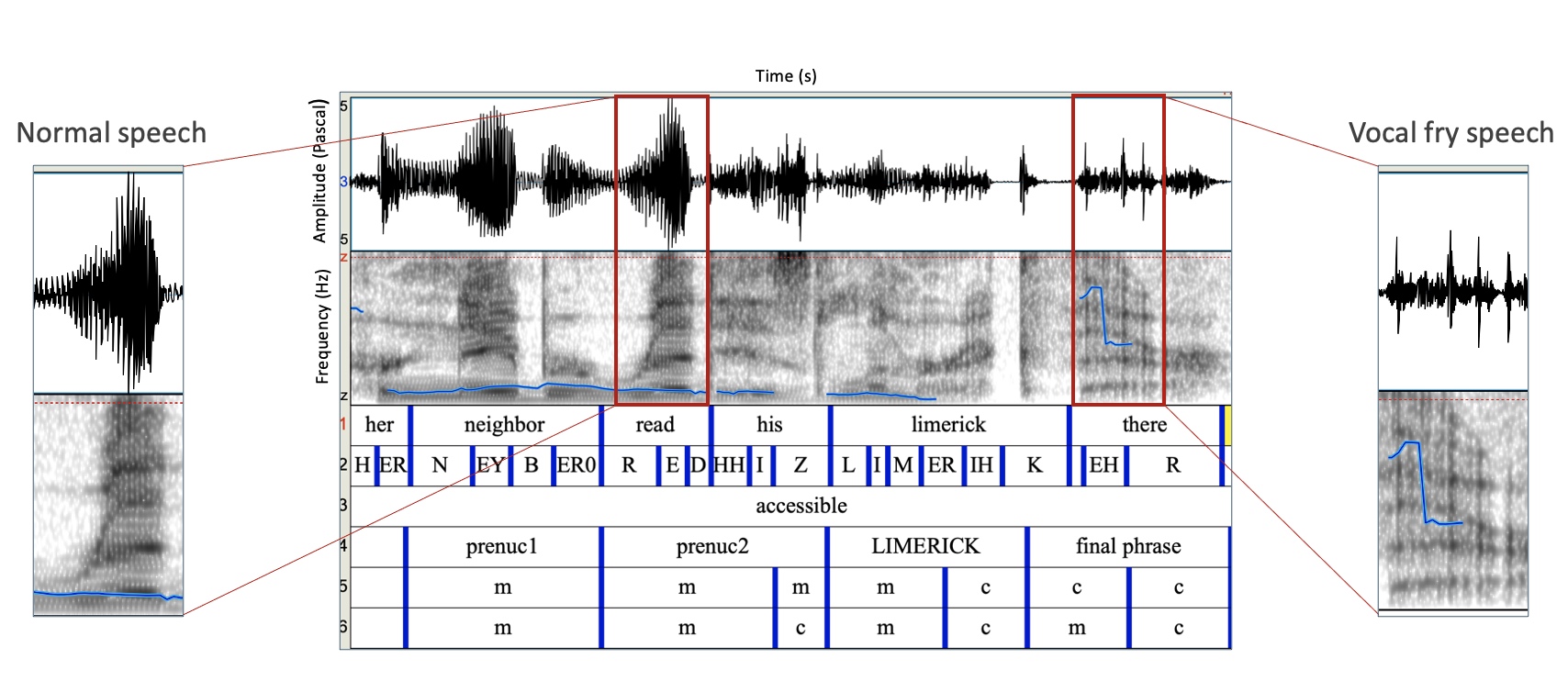
Speech with vocal fry (right) vs normal speech (left). We can see the distinctive pattern difference (e.g. irregular pitch and irregular periodicity) in both the spectrogram and the acoustic waveform.
Breaking long-used algorithms
This irregular periodicity may cause automatic speech recognition (“speech-to-text”) and speaker verification systems to underperform and tend to reduce recognition performance [1].
There are two main reasons for that. First, the training data does not include enough instances of vocal fry segments, if any at all. Second, the typical signal processing suitable for standard speech processing is not adequate for detecting vocal fry. The reason is as follows. Speech processing is done by working in windows, where it is assumed that the signal’s statistics within the window are constant (it is called stationarity). To have a good reliable signal representation, the processing windows should include several pitch periods. However, since the pitch period is very low in vocal fry, the standard window duration of 20–25 ms is not adequate.
Early attempts that tackled the problem of identifying vocal fry segments were based on ad-hoc signal processing techniques [2–8]. Recent methods used deep neural networks but were designed for unique and small datasets and used a fixed pre-processing method on the input (MFCC, STFT, etc.).
A new approach — DeepFry
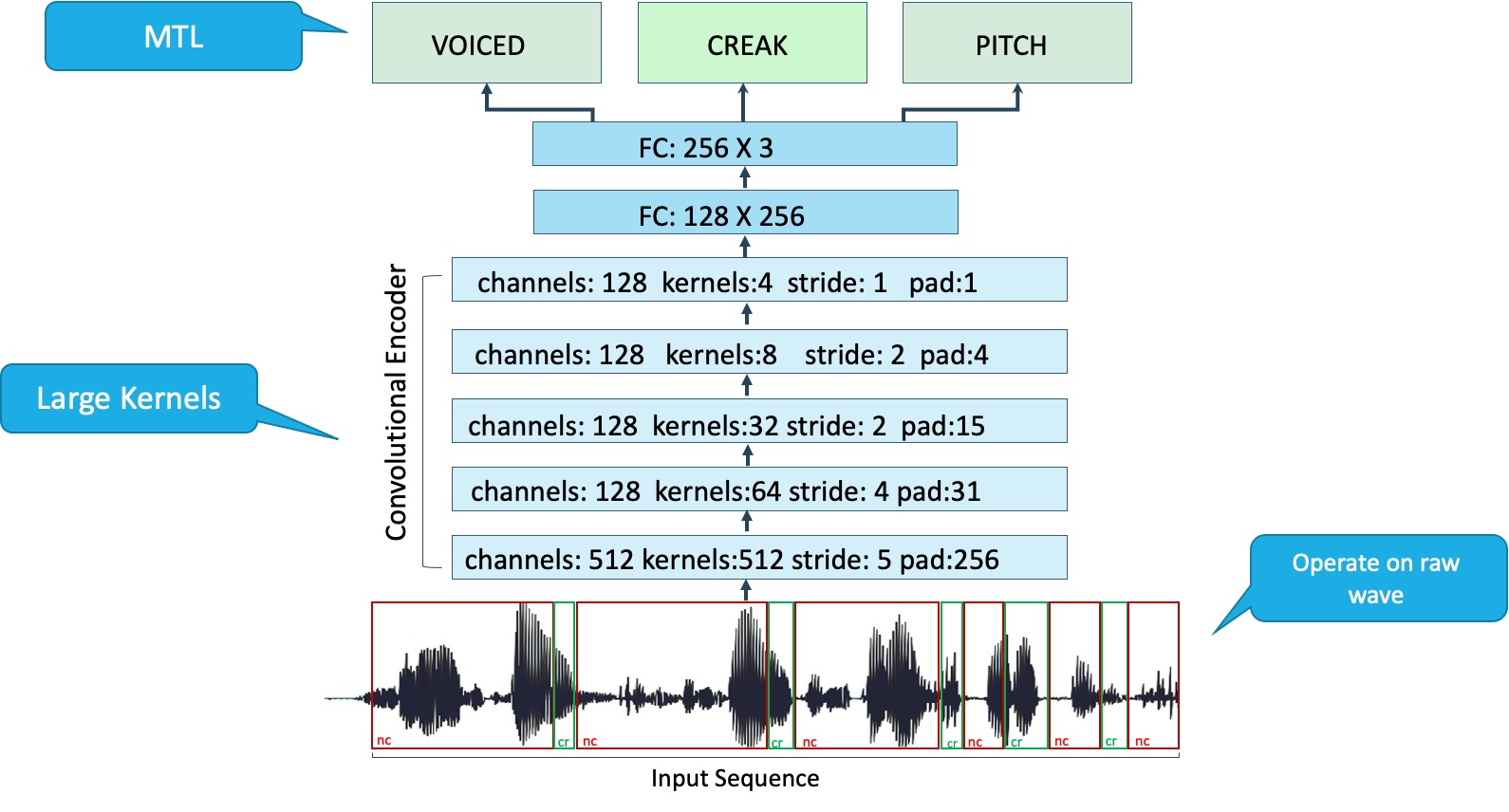
Motivated by these resolutions, in our paper DeepFry, we tackle the problem by introducing several innovative components in our model.
Operating on the raw waveform
Vocal fry can span over varying durations. For example, it can be very short or longer than half a second. To capture sounds defined over shorter and longer periods, including vocal fry, and overcome the issue posed by using pre-processing methods, the input to the network is the raw acoustic wave, split into frames of varying durations without any pre-processing methods. This bypasses the ‘stationarity’ principle and windowing required by MFCCs and STFTs, allowing for more flexibility to uncover regions of creak.
Large receptive field
As mentioned above, vocal fry can have varying durations. We wanted to ensure that our encoder would have a receptive field large enough to capture the varying periodicity of vocal fry to learn a good latent representation of the signal. The standard approach to achieve such representation is to use an encoder, which in our case is implemented as a fully-convolutional neural network, which consists of large filters (kernels) compared to standard ones used in the domain of speech.
Multi-task learning framework
We trained our model to predict 3 tasks simultaneously: vocal fry (creak), voicing, and pitch: The auxiliary tasks are:
- Voicing — while vowels and certain consonants such as the nasals “m” and “n” involve vocal cord vibration, other consonants do not, such as “p t k”. Vocal fry can be present only in voiced frames when training the network, so we condition the prediction of vocal fry on the prediction of voicing.
- Pitch — due to the correlation between the tasks of detecting vocal fry and pitch, we added the task of detecting if a given frame had pitch or not.
Our ablation experiments show that these additional tasks had a large contribution to the prediction of vocal fry.
In our paper, we also introduced another version of the model. We replaced the convolutional encoder with HuBERT [9]. HuBERT, is a state-of-the-art model trained in a self-supervised fashion that has a very good latent representation of the speech signal. We keep the HuBERT model fixed, such that only the top level is fine-tuned on predicting voicing, creak and pitch. Results show that both methods improve the detection of vocal fry regions, with HuBERT being better on unseen data. It is, however, important to note that our model has less than 5M parameters and was trained only on 24 minutes of speech, while HuBERT is a much larger model with 90M parameters, pre-trained on 960 hours of Librispeech and also requires the overhead of extracting features for every audio file.
Final notes
In this post, we introduced vocal fry, explained why its detection is difficult, and proposed two methods to detect it. However, there is still work to be done. For instance, we only used labeled instances of vocal fry in our training routine, but we had very little speech data where vocal fry has been explicitly labeled; such labeling requires phonetic expertise and is difficult and time-consuming. We could further improve detection by using our trained model to label more segments in a semi-supervised fashion and improving the model further.
It is also important to point out that the latest state-of-the-art ASR models, such as HuBERT, do manage to handle vocal fry. However, these models are very large and are not easily accessible without intensive computational resources.
For more details on our implementation, our repo for vocal fry detection is publicly available: https://github.com/bronichern/DeepFry/.
References:
[1] R. Ogden, “Turn transition, creak and glottal stop in Finnish talk-in-interaction” Journal of the International Phonetic Association, vol. 31, no. 1, pp. 139–152, 2001.
[2] S. Vishnubhotla and C. Y. Espy-Wilson, “Automatic detection of irregular phonation in continuous speech,” in Ninth International Conference on Spoken Language Processing, 2006.
[3] C. T. Ishi, K.-I. Sakakibara, H. Ishiguro, and N. Hagita, “A method for automatic detection of vocal fry,” IEEE transactions on audio, speech, and language processing, vol. 16, no. 1, pp. 47–56, 2007.
[4] A. Cullen, J. Kane, T. Drugman, and N. Harte, “Creaky voice and the classification of affect,” Proceedings of WASSS, Grenoble, France, 2013.
[5] T. Drugman, J. Kane, and C. Gobl, “Resonator-based creaky voice detection,” in Thirteenth Annual Conference of the International Speech Communication Association, 2012.
[6] S. Scherer, J. Kane, C. Gobl, and F. Schwenker, “Investigating fuzzy-input fuzzy-output support vector machines for robust voice quality classification,” Computer Speech & Language, vol. 27,
no. 1, pp. 263–287, 2013.
[7] J. Kane, T. Drugman, and C. Gobl, “Improved automatic detection of creak,” Computer Speech & Language, vol. 27, no. 4, pp. 1028–1047, 2013.
[8] T. Drugman, J. Kane, and C. Gobl, “Data-driven detection and analysis of the patterns of creaky voice,” Computer Speech & Language, vol. 28, no. 5, pp. 1233–1253, 2014.
[9] Hsu, Wei-Ning, et al. “Hubert: Self-supervised speech representation learning by masked prediction of hidden units.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2021): 3451–3460.