Self-supervised Speaker Diarization
Joseph Keshet

Joseph Keshet

Self-supervised Speaker Diarization
We propose an entirely unsupervised deep-learning model for speaker diarization. Specifically, the study focuses on generating high-quality neural speaker representations without any annotated data, as well as on estimating secondary hyperparameters of the model without annotations.
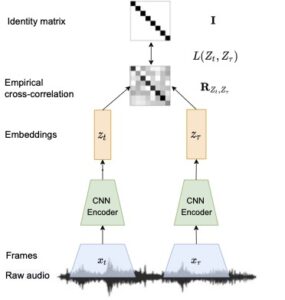
The speaker embeddings are represented by an encoder trained in a self-supervised fashion using pairs of adjacent segments assumed to be of the same speaker.
The trained encoder model is then used to self-generate pseudo-labels to subsequently train a similarity score between different segments of the same call using probabilistic linear discriminant analysis (PLDA) and further to learn a clustering stopping threshold.
We compared our model to state-of-the-art unsupervised as well as supervised baselines on the CallHome benchmarks. According to empirical results, our approach outperforms unsupervised methods when only two speakers are present in the call, and is only slightly worse than recent supervised models.
Yehoshua Dissen, Felix Kreuk, Joseph Keshet, Self-supervised Speaker Diarization, preprint, 2022.